Towards Scaling Laws for Coding Agents
Anthropic recently demonstrated that claude-code with parallel agents can build a C compiler in Rust from scratch in just 14 days. The headline numbers are attention-grabbing — roughly 200,000 lines of code, capable of compiling the Linux kernel and other software like Doom and postgres!
I immediately paid attention to this article since Nicholas Carlini was the author on the blog. He is well-known in AI red-teaming, and adversarial attacks. And from my past interactions with him at Google DeepMind, I know how strong a researcher he is.
Usually for human developed code a lot of design decisions for why something was done is tribal knowledge so it's not really possible to figure out "Why" something was done? Fortunately however the way this code was developed makes it possible to do something rare: code archaeology. Because of the meticulous book-keeping of ideas and tasks by the agents, it was entirely possible to analyze how the system evolved, decision by decision, layer-by-layer. By analyzing the full commit history we were able to model the scaffolding that was used to generate the repository and do some simple analysis of scaling laws for parallel claude-code agents.
1. Code Archaeology
Our first task was to understand how the 16 agents interacted to evolve the code for the compiler over time. To do so it helps to visualize how the code evolved over time. My first step was to create a time-lapse video of the entire 14-day development window, visualizing commit density, active agents, and subsystem focus. You can see the video here: Time-lapse video: https://youtu.be/c9P89fe4WQk The full code and the original interactive HTML is also available at https://github.com/pushpendre/claudes-c-compiler Some interesting takeaways from this visualization are that within the first 4 hours, the LLM had already written the first 10K lines of code focusing almost exclusively on the parser. Borrowing an analogy from chess, it felt like the LLM was blitzing through well known theory. Even though the video is good to get a sense of what was going on, unfortunately, it's too quick and not "information dense" enough. The following graph does a much better job of conveying a lot of information. This graph plots as a function of time: a) the test pass rate for different tests suites, b) The number of commits and the lines of code, and c) The number of commits per hour. It also marks the times where the tasks were cleared, either manually or automatically because the progress was stagnating.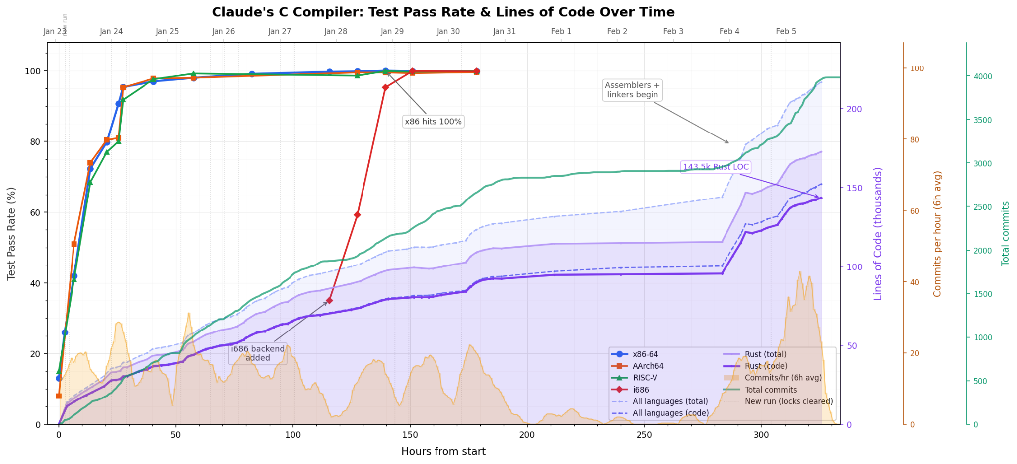 We can clearly see within just 24 hours the compiler was already passing 95% of tests. The progress quickly asymptoted on the tests after 2 days but curiously a lot more code was added between hours 50 and 100 (i.e. days 3 and 4). Turns out the agents were reset and tasked with improving the runtime performance of the compiler. In hours 100 to 150 the compiler was primarily bringing up the x86 backend. Hours 150 to 250 were devoted to refactoring, reducing tech debt, and optimizing generated code. Finally for hours 250 onwards the dependency on GCC's assemblers and linkers was removed.
We can clearly see within just 24 hours the compiler was already passing 95% of tests. The progress quickly asymptoted on the tests after 2 days but curiously a lot more code was added between hours 50 and 100 (i.e. days 3 and 4). Turns out the agents were reset and tasked with improving the runtime performance of the compiler. In hours 100 to 150 the compiler was primarily bringing up the x86 backend. Hours 150 to 250 were devoted to refactoring, reducing tech debt, and optimizing generated code. Finally for hours 250 onwards the dependency on GCC's assemblers and linkers was removed.
2. Agent Scaling Laws: Actors vs Time
Although Anthropic did not release the scaffolding for the compiler it is possible to reverse engineer it because of the meticulous note-taking by the agents which maintained theideas/ folder as an intake queue for proposed tasks, and the current_tasks/ folder which listed the tasks. This information was sufficient to take a stab at reproducing the scaffolding that would have generated the compiler. We have open sourced the scaffolding code at https://github.com/vizopsai/async_compiler_factory
In order to keep the budget low, we only ran it with one agent for 60 minutes and tested its progress on a small suite of just 18 tests. Using this scaffolding we can extrapolate some "inference time" scaling laws! For example, we can measure whether the test-pass rate improves linearly as we add more agents or if it is better to keep the number of agents low and let it work for a longer period of time.
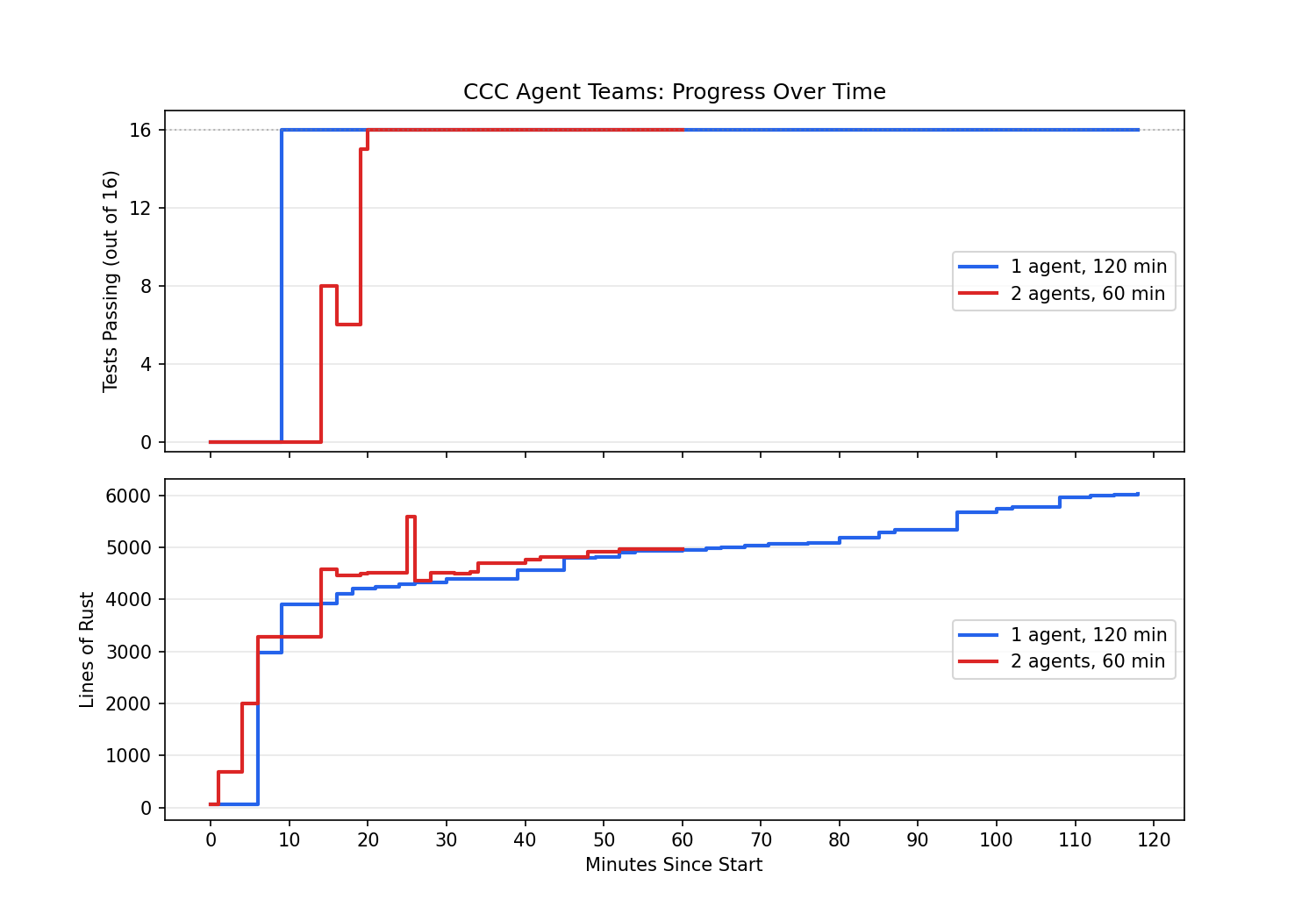
To test the scaffolding, I ran a small test to compare the efficacy of one agent running for two hours vs two agents running for one hour and the results are below. Both of the agents were tasked with passing 16 tests that involved compiling programs like fizzbuzz, basic recursion, pointers, arrays, structs etc. The reproduced scaffolding was able to pass these tests within the first 20 minutes, and in fact one agent running longer produced more lines of code. So the jury on the utility of parallel agents is still out.
These two runs cost $153 in total. The scaffolding, the produced code, and the analysis code and plots are also open sourced and available at https://github.com/vizopsai/async_compiler_factory