We Achieved 29% Better Reasoning by Teaching LLMs to Learn from Their Own Failures
By Rishav ·
February 22, 2026 ·
10 min read
This is Part 2 of our prompt optimization series. In Part 1, we introduced PromptGrad — a gradient-descent-inspired optimizer that beat the state of the art by 18% across five benchmarks. In this post, we tackle a different signal: when an AI stumbles on a problem but gets it right on a second try, something changed in its reasoning — and that difference is a goldmine for optimization.
Executive Summary
> Introducing VizopsAI ContraPrompt: a system that watches AI fail then succeed on the same problem, extracts what changed, and bakes those patterns into the prompt permanently. No fine-tuning required.
> - +29% on multi-hop reasoning, +19% normalized across six benchmarks — by mining the gap between a model's first-pass failures and its self-corrections.
- Real-world compliance gains: +18% on GDPR detection — contrastive optimization transfers from academic benchmarks to regulatory tasks.
- Cost arbitrage: Optimized prompts on a $0.25/1M-token model approach the quality of models costing 30–60×more, with fully auditable, human-readable rules.
- Free diagnostic: Test 20 failed examples with a retry nudge. If >30% self-correct, ContraPrompt will deliver strong gains on your task.
Models know more than they show. We built a system to capture what they're holding back.
Ask Claude a multi-hop question — one that requires connecting facts across multiple documents — and it stumbles. It grabs the first relevant fact and jumps to a conclusion, skipping the verification step.
Now give it a second chance. Just say: "Your answer was incorrect. Think more carefully."
30–40% of the time, it nails it. Same model, same question, same context. The only thing that changed was a generic nudge. The knowledge was there the entire time — the model just didn't deploy the right reasoning strategy on the first try.
Every developer who's worked with LLMs has noticed this. What nobody had done — until now — was systematically mine that gap between failure and success, extract the patterns that explain the difference, and bake them permanently into the prompt.
We're calling it Contrastive Prompting (or ContraPrompt for short).
Lets walk through an example
Here's an actual HotPotQA problem from our experiments. The question requires connecting information across two Wikipedia paragraphs:
Question: "Are the directors of 'Jaws' and 'The Color Purple' the same person?"
Attempt 1 (Failed — score 0.2):
"Jaws was directed by Steven Spielberg. The Color Purple is a novel by Alice Walker that was adapted into a film. Based on the information provided, I cannot confirm they share the same director."
The model found one fact (Spielberg directed Jaws) but hedged on the second instead of verifying it in the context. It had the answer — Spielberg directed both — but didn't commit to checking.
Attempt 2 (After nudge — score 1.0):
"Jaws (1975) was directed by Steven Spielberg [Paragraph 1]. The Color Purple (1985) was also directed by Steven Spielberg [Paragraph 3]. Yes, both films were directed by the same person: Steven Spielberg."
Same model. Same context. The difference: on the second attempt, it verified each fact against a specific paragraph before combining them.
ContraPrompt's extracted rule:
"When answering comparison questions, explicitly locate and cite the relevant fact for EACH entity before stating the comparison. Do not assume or hedge — verify against the source."
That rule, extracted from watching the model fail then succeed, improved performance across hundreds of similar questions. One contrastive pair → one rule → systematic improvement.
How ContraPrompt Works
The method has three phases, each building on the last.
Phase 1: Multi-Attempt Solving
For each training example, ContraPrompt gives the model up to three shots:
- Attempt 1: Solve with the current prompt. No help.
- Attempt 2: If it failed — retry with generic feedback: "Your previous answer was incorrect. Think more carefully."
- Attempt 3: If it still failed — retry with specific feedback about the error type: "Your answer had a reasoning error in evidence synthesis. Address this."
The feedback is deliberately calibrated. Attempt 2's vague nudge forces the model to reconsider its entire approach. Attempt 3's targeted hint focuses it on the specific weakness.
This generates a rich dataset: for each problem, we have the model's worst attempt, its best attempt, and everything in between.
Phase 2: Contrastive Mining
Now the key step: ContraPrompt scans the attempts and identifies contrastive pairs: problems where the model failed initially but succeeded on retry.
These pairs are gold. When you compare a failed attempt and a successful attempt on the exact same problem from the exact same model, the only variable that changed is the reasoning strategy. The difference between attempts tells you precisely what was missing.
ContraPrompt mines at two levels:
- Error correction pairs (failed → succeeded): What fixed a total failure? These reveal missing reasoning steps — like the "verify each fact" rule above.
- Refinement pairs (partially correct → fully correct): What improved an already decent answer? These reveal subtle optimizations — like better output formatting or more precise entity matching.
A stronger analysis model (Sonnet-class) examines each pair and extracts structured rules describing the pattern. This separation — using a stronger model for analysis while keeping the task model fixed — is critical. You want the smartest analyst reviewing the failures, even if a cheaper model runs the actual task.
Phase 3: Soft Validation and Progressive Accumulation
Extracted rules are validated — but with a deliberately permissive threshold. ContraPrompt only rejects rules that actively hurt performance (delta < -2%). Rules that seem neutral? They stay.
This sounds reckless. It's not. Here's why.
Prompt rules aren't independent — they interact. A rule that does nothing on its own might combine with another rule to produce a significant improvement. Strict validation (requiring each rule to prove its worth individually) misses these synergies. Our ablation data is clear: soft validation outperforms strict validation by 7% on average.
The analogy: strict validation is like only hiring people who've already proven themselves in the exact role. Soft validation also hires people who haven't hurt anything — and some of them become stars once they're on the right team.
Validated rules accumulate in a progressive rule bank that persists across optimization iterations. Rules that stop helping are periodically pruned. The bank self-maintains, building compound improvements over time — each iteration's discoveries combining with previous ones.
Results: Dominant on Deep Reasoning
All results use Claude Haiku 4.5 — a small, cost-efficient model. That's deliberate: we're optimizing the model you can actually afford to run at scale.
| Benchmark | Task Type | GEPA | PromptGrad | ContraPrompt | vs. GEPA |
|---|
| HotPotQA | Multi-hop reasoning | 36.8% | 45.8% | 47.6% | +29% |
|---|
| GPQA Diamond | Graduate science | 64.2% | 66.9% | 68.2% | +6% |
| BBH | 27 reasoning tasks | 87.6% | 89.8% | 88.3% | +1% |
|---|
| MMLU-Pro | Professional knowledge | 80.2% | 79.6% | 80.0% | ~0% |
| AIME 2025 | Competition math | 43.3% | 46.7% | 36.7% | -15% |
|---|
| GDPR-Bench Android | GDPR compliance detection | ~8% | ~5% | ~26% | +18.2% |
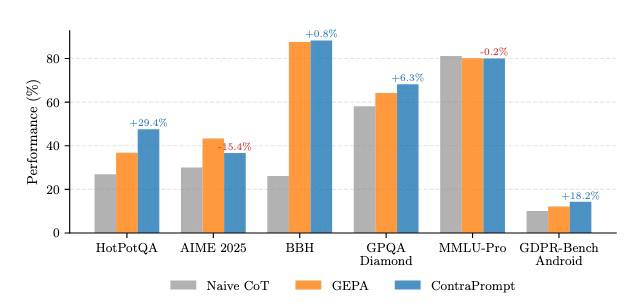 Performance comparison across six benchmarks. ContraPrompt shows dominant gains on reasoning-heavy tasks (HotPotQA +29%, GDPR-Bench +18.2%).
Normalized: 0.741 vs. GEPA's 0.624 — a 19% improvement across six benchmarks.
Performance comparison across six benchmarks. ContraPrompt shows dominant gains on reasoning-heavy tasks (HotPotQA +29%, GDPR-Bench +18.2%).
Normalized: 0.741 vs. GEPA's 0.624 — a 19% improvement across six benchmarks.
+29% on Multi-Hop Reasoning
HotPotQA is multi-hop QA is exactly the kind of task where models self-correct on retry. The model has the facts. It just doesn't assemble them correctly on the first pass. A nudge triggers more systematic evidence gathering. ContraPrompt captures what "more systematic" looks like and makes it permanent.
-15% on Competition Math
AIME 2025 is the only benchmark where ContraPrompt underperforms.
Why it fails: Competition math is hard. When Haiku 4.5 can't solve an AIME problem on the first attempt, it almost never succeeds on retry either. The retry success rate is near zero, which means ContraPrompt has no contrastive pairs to mine. Without contrastive signal, the method falls back to basic failure analysis — which is weaker than GEPA's evolutionary search.
Why AIME is the exception, not the rule: Across every other benchmark — including GDPR-Bench Android, a real-world compliance task far removed from academic reasoning — ContraPrompt matches or dominates. The GDPR-Bench result is especially telling: contrastive mining generalizes beyond multi-hop QA to regulatory analysis, confirming that the method works wherever models can self-correct on retry.
The practical diagnostic: ContraPrompt's effectiveness maps directly to retry success rate. This gives you a free diagnostic before you invest in optimization:
| Retry Success Rate | ContraPrompt Likely Outcome |
|---|
| >30% | Strong improvement (+10–30%) |
|---|
| 15–30% | Moderate improvement (+3–10%) |
| <15% | Use PromptGrad or GEPA instead |
|---|
Test 20 failed examples with a generic nudge. Count how many succeed. You'll know in minutes whether ContraPrompt is the right tool.
Why This Matters
1. ContraPrompt productizes a Universal Developer Intuition
"Just ask it again" is the most common workaround in LLM development. Everyone does it. Nobody had turned it into a systematic optimization pipeline.
ContraPrompt takes a manual, per-query hack and transforms it into an automated system that extracts, validates, and deploys self-correction patterns at scale. The result: models that get it right the first time, every time, without runtime retries.
2. It Targets the Highest-Value Failure Mode
The tasks where ContraPrompt shines — multi-hop reasoning, graduate-level science, complex analytical work — are exactly the tasks enterprises pay the most for. Legal document review. Medical literature synthesis. Financial due diligence. Multi-source intelligence analysis.
The GDPR-Bench Android result (+18.2%) makes this concrete: detecting GDPR compliance violations in Android app privacy policies is a real-world regulatory task — not an academic exercise. ContraPrompt's contrastive mining discovers the same verification patterns that human compliance reviewers learn through experience. If your enterprise needs reliable regulatory, legal, or policy analysis, this is the method that generalizes from academic reasoning benchmarks to actual compliance workloads.
These are tasks where the model can do it but doesn't always do it. That inconsistency is the most expensive problem in production LLM deployment, and it's precisely what ContraPrompt eliminates.
ContraPrompt vs. PromptGrad: Complementary, Not Competing
If you read our PromptGrad post, the natural question is: which one do I use?
They solve different problems:
| Signal source | "What went wrong?" | "What changed when it went right?" |
|---|
| Best when | Diverse failure modes, systematic errors | Model can self-correct, deep reasoning |
| Biggest win | AIME +8%, BBH +3% | HotPotQA +29%, GDPR-Bench +18.2%, GPQA +6% |
|---|
| Validation style | Strict (rule must help) | Soft (rule must not hurt) |
| Failure on | Knowledge-bound tasks | Tasks where retries don't help |
|---|
They never win on the same benchmark. That's not a coincidence — it's evidence that they capture fundamentally different optimization signals. The full comparison and decision framework is in our final post in this series.
Rishav is a Founding AI Engineer at VizopsAI. He specializes in reinforcement learning and prompt optimization, with research experience at Mila, Wells Fargo, and Pixxel. He holds a B.Tech from BITS Pilani.
VizopsAI builds the secure runtime for enterprise AI applications. vizops.ai