Engineering Virality: How We Taught AI to Stop Being 'Average'
In the attention economy, 'average' is invisible.
Every CMO, CIO, and executive leader today faces the same paradox with Generative AI: It is incredibly smart, but it is also incredibly average. If you use a standard frontier model (like GPT-5 or Claude Sonnet 4.5) to write a marketing email, it will give you the most statistically probable, "safe" answer. For tasks like summarizing meetings or writing SQL queries, safety is a feature. But when you are fighting for a customer's attention in a crowded inbox, "average" is invisible. You cannot win back a dormant customer by aiming for the median outcome. To break through the noise, you need to swing for the fences. The problem is that standard AI models are mathematically incapable of taking that swing. They are trained to revert to the mean. To compensate for this lack of creativity, businesses historically rely on two expensive crutches:- Bribe — Offering a 10-20% discount to force an open (eroding your margins and commoditizing customer loyalty)
- Clickbait — Using deceptive subject lines to force a click (eroding your brand)
- Mean Click Through Rate (CTR): 1.57%
- 38% of headlines fail completely (CTR < 1%)
- Only 2.2% go viral (CTR > 5%)
- Q0.5 (Median): The "Base Hit." (What happens most of the time?)
- Q0.9 (Upper Tail): The "Home Run." (What happens if this lands?)
- Q0.99 (Extreme): The "Grand Slam." (Viral potential.)
- Generate: The model creates 4 candidate headlines.
- Score: Our Distributional Reward Model scores each one.
- Advantage: We compute the advantage using the group-relative baseline.
- Update: We update the policy to increase the probability of high-reward outputs.
- Why Gemini? We excluded the Claude models from judging this specific round to eliminate "Self-Preference Bias" (models tending to prefer their own output style).
- Originality: DistRL dominated with 6.45 vs Claude's 4.28 (+2.17).
- Coherence: DistRL achieved a perfect 10.00 score vs Claude's 9.97.
- Distributional RL Model — The risk-seeking approach
- Standard RL Model — The mean-optimizing baseline
- Input Context: 2,500 tokens per email.
- Volume: 1,000,000 emails per day.
- Frontier Price: ~$3.00 per 1M tokens (Blended).
- Frontier Bill: $7,500/day
- Vizops Bill: ~$40/day in GPU costs = $14,600/year.
We challenged ourselves: *Can an AI agent deliver viral-level engagement without the brand risk of clickbait or the margin erosion of discounts?
The answer was a resounding 'YES.' But the path to getting there wasn't by prompting a generalist model. We had to change the mathematics of how an LLM learns.
Swing for the Fences
We chose headline generation as our proving ground because headlines are the gatekeeper of attention. Before a reader experiences your content, they decide in milliseconds whether to click based on a few words. A brilliant article with a mediocre headline is invisible; a compelling headline can make average content go viral. To benchmark our approach, we analyzed the Upworthy Dataset—a collection of A/B tested headlines from one of the internet's most viral publishers. This dataset captures real user behavior at scale, making it an ideal proxy for high-stakes engagement. The data revealed a brutal power law:To optimize headline creation, most teams would use Standard Reinforcement Learning (RL). But here's the catch — Standard RL optimizes for the Mean (Expected Value). It looks at that 1.57% average and teaches the model to chop off the "long tail" of outcomes to prevent the model from saying anything crazy. In doing so, it also prevents the model from saying anything brilliant.
Let's think of a baseball player.
Classic RL is like a player coached to minimize strikeouts. It calculates the "average" outcome of every swing. Since swinging for the fences carries a high risk of missing, Standard RL plays it safe. It hits a lot of singles (mediocre headlines), but it never hits a home run.
To win, we need to change the coaching strategy. We don't teach the model to look at the average. We teach it to see the entire range of possibilities—from "total flop" to "viral sensation." We call this "Distributional RL".
Instead of predicting a single "average" number, our reward model predicts multiple quantiles of the potential outcome. It doesn't just ask "How good is this?"; it asks "What are the odds this goes viral?"
# We track the full spectrum of outcomes
Quantiles = [0.1, 0.25, 0.5, 0.75, 0.9, 0.95, 0.99]
This gives the model a richer picture of every option:
With this visibility, we can implement a Risk-Seeking Optimization strategy. We use a weighted reward formula to tell the model: "I value the upside potential more than the safety of the median."
# The "Swing for the Fences" Formula
Reward = Q_0.5 + 0.5 (Q_0.9 - Q_0.5)
Translation: We start with the median performance (Q0.5), but we add a massive bonus based on how high the upside is (Q0.9). This mathematically forces the model to prefer headlines with "viral variance."
Building the Coach
How do we actually build this? We needed a Reward Model that could output these multiple predictions simultaneously. We built a customDistributionalRM using a DistilBERT encoder (for speed). Instead of a single output head, we use a multi-head output that predicts all 7 quantiles at once.
class DistributionalRM(nn.Module):
def __init__(self, quantiles=[0.1, 0.25, 0.5, 0.75, 0.9, 0.95, 0.99]):
self.encoder = AutoModel.from_pretrained("distilbert-base-uncased")
self.head = nn.Sequential(
nn.Linear(768, 256), nn.ReLU(), nn.Dropout(0.1),
nn.Linear(256, 256), nn.ReLU(), nn.Dropout(0.1),
nn.Linear(256, len(quantiles)) # Output all quantiles
)
To train this model, we can't use standard error (MSE) because MSE tries to squash everything to the average. We used Huber Quantile Loss, adapted from advanced game-playing AI (like QR-DQN).
L_τ(y, q) = |τ - 1_{y<q}| × huber(y - q, κ)
Think of this loss function as a coach that understands "luck." It doesn't punish the model severely for missing an outlier; instead, it gently corrects the model's estimation of probability. This allows the model to learn the shape of the distribution without getting confused by the noise inherent in viral data.
The Matchup
The real test wasn't whether DistRL worked in isolation—it was whether it could outperform the best alternative available today. We set out to find the toughest opponent and beat it on its home turf. We pitted our Small 14B Model (fine-tuned with DistRL) against Claude Sonnet 4.5. However, we didn't just give Claude a generic prompt. We used DSPy MIPROv2 to mathematically optimize the prompts specifically for Claude. Why did we do this? There is an inherent bias in prompt optimization: DSPy optimizes based on the model's own preferences. By using prompts that Claude "liked" best, we were playing on its home turf. We intentionally stacked the deck against ourselves to prove a point: Even when the Frontier Model is given every advantage, our DistRL approach still wins. To build our challenger, we fine-tuned Qwen 2.5 (14B) using Group Relative Policy Optimization (GRPO) with LoRA. Standard GRPO is powerful, but we added a distributional twist. For every training step:Unlike standard GRPO, our reward signal wasn't a flat number. It incorporated the distributional prediction (upside potential), effectively coaching the model to ignore "safe" answers and hunt for viral outliers.
Judges
To rigorously evaluate the results, we employed a panel of four independent frontier judges: Claude Opus 4.5, Claude Sonnet, GPT-5.1, and Gemini 2.5 Pro. Each judge scored headlines on a 1-10 scale across five dimensions: Attention, Coherence, Clarity, Viral Potential, and Originality. However, for the head-to-head comparison against Claude Sonnet, we relied primarily on Gemini 2.5 Pro.Outperforming the Frontier
Head-to-Head: DistRL vs. Claude Sonnet 4.5
The data from Gemini 2.5 Pro confirmed our hypothesis. Our specialized model didn't just compete with the optimized Frontier setup; it beat it. The Results (Gemini Judge):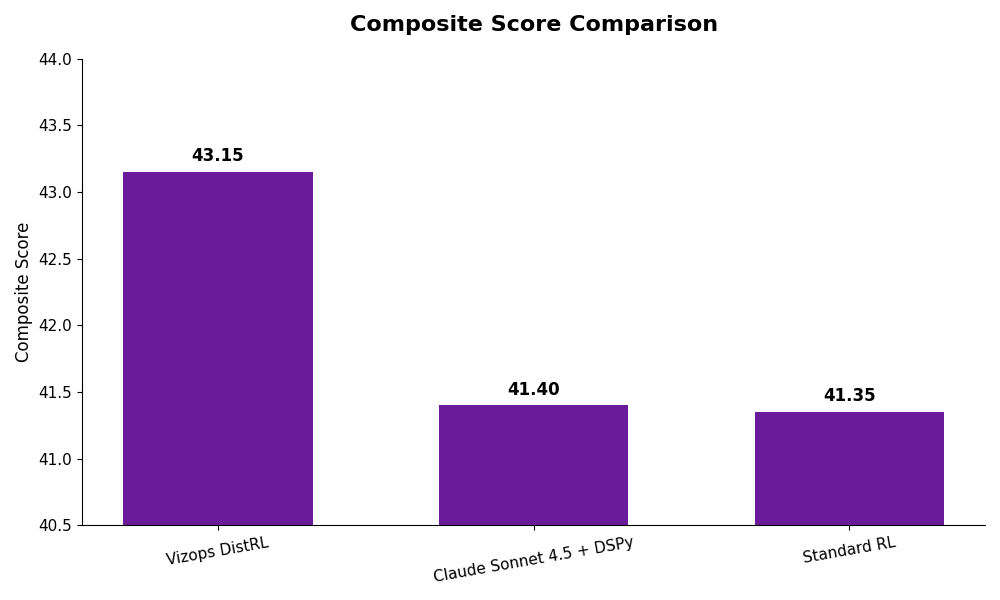 DistRL beat Claude by 1.75 points.
The difference wasn't just in the score; it was in the style. The gap was driven by two specific factors:
DistRL beat Claude by 1.75 points.
The difference wasn't just in the score; it was in the style. The gap was driven by two specific factors:
Because our model was mathematically rewarded for risk-taking, it produced punchier, uniquely framed angles, whereas the Frontier model—even with optimized prompts—reverted to safe, "assistant-like" patterns.
Eliminating Bias
Even when we expanded the pool to include all Non-Claude Judges (Gemini + GPT) to average out any specific model biases, DistRL maintained its lead:| Method | Non-Claude Composite Score |
|---|
| Vizops DistRL (14B) | 40.82 |
|---|---|
| Claude Sonnet 4.5 (DSPy) | 40.71 |
Our small, specialized model matched or exceeded the frontier model's performance at a fraction of the compute cost.
DistRL vs. Standard RL
The most telling comparison is between our Distributional RL approach and Standard RL (optimizing for the mean), keeping the model architecture identical. Using normalized Z-scores across the independent judges, we see exactly how the "Risk-Seeking" optimization shifts the model's behavior.| Metric | DistRL | Standard RL | Winner |
|---|
| Viral Potential | +1.00 | -1.00 | DistRL |
|---|---|---|---|
| Originality | +1.00 | -1.00 | DistRL |
| Attention | +0.50 | -0.50 | DistRL |
|---|---|---|---|
| Coherence | 0.00 | 0.00 | Tie |
| Clarity | 0.00 | 0.00 | Tie |
|---|---|---|---|
| Total Impact | +2.50 | -2.50 | DistRL |
DistRL dominates on the "Business Metrics" (Viral Potential, Originality, Attention) while maintaining exact parity on "Safety Metrics" (Coherence, Clarity). This confirms our hypothesis: Distributional RL teaches the model to take creative risks without hallucinating.
See the Difference Yourself
Try the models: We've open-sourced both models so you can test them yourself.
Abstract scores are one thing, but looking at the actual output shows why DistRL wins. It captures voice, emotion, and "punchiness" that standard models smooth over.
Example 1: Geek Girls Anthem
Lede: "If you're a lady-human of the geek persuasion, you've definitely had a run-in or two with dude-geeks who think you just aren't geeky enough..."| Method | Headline |
|---|
| Claude | "This Epic Song Shuts Down Every Dude Who Says Women Aren't Geeky Enough" |
|---|---|
| Vizops DistRL | "Lady Geeks Strike Back with Nerd-Tastic Song: You Don't Define My Geekery" |
| Standard RL | "Geeky Ladies Roast Dude-Geeks in Hilarious Nerd-Tastic Song: Watch Famous Faces" |
|---|
Example 2: Disability PSA
Lede: "If you've ever talked to someone with a disability, you've probably noticed that they're people and not just their disabilities..."| Method | Headline |
|---|
| Claude | "People With Disabilities Share the Hilariously Obvious Things You Need to Stop Doing Right Now" |
|---|---|
| Vizops DistRL | "Stop the Awkward! People With Disabilities Reveal Hilarious Yet Heartfelt Tips for Getting It Right" |
| Standard RL | "Stop Awkward Moments Cold: People with Disabilities Reveal Their Simple Tips for Respectful Interaction" |
|---|
Example 3: Marijuana for Epilepsy
Lede: "Marijuana is a big deal here in Colorado... one little girl, named Charlotte, considers it a lifesaver. Because she has pediatric epilepsy which causes 400 seizures A WEEK."| Method | Headline |
|---|
| Claude | "This 5-Year-Old Had 400 Seizures a Week Until She Found This Miracle Plant" |
|---|---|
| Vizops DistRL | "Miracle Weed Saves Little Charlotte from 400 Seizures a Week: The Emotional Journey of a Pediatric Epilepsy Breakthrough" |
| Standard RL | "Miracle Weed Saves Little Girl from 400 Seizures a Week: The Emotional Story Behind the Life-Changing Science" |
|---|
Economics of High Performance
We have proven that a specialized agent can out-create a frontier model. But for a P&L owner, superior performance is only half the equation. The other half is economic feasibility at scale. Let's assume you're a large e-commerce firm that is running a retargeting program that sends 1 million emails a day. To get a frontier model (like Claude Sonnet 4.5) to write high-quality subject lines, you cannot just send a simple prompt. You have to force-feed it context via a system prompt containing brand guidelines, edge cases, and user history to prevent it from hallucinating. When we did the back-of-the-envelope math on using a frontier model for this volume, the numbers were prohibitive:For a retargeting campaign, a $2.7 million bill destroys the ROI before you send a single email. This forces most companies into a "Quality vs. Scale" trade-off: either you pay the premium for smarts (and destroy margin), or you settle for a "dumber," cheaper model (and destroy engagement).
We eliminated the trade-off.By using Unsloth for efficient fine-tuning and vLLM for serving, we replaced a massive API bill with cheap commodity hardware.
We achieved better engagement metrics (beating Claude by 1.75 points) with 99% reduction in cost. You don't have to choose between breaking the bank or being boring.
The Age of Specialized Intelligence
We are entering a new phase of AI adoption. For general tasks—summarizing meetings or writing code snippets—massive generalist models are fantastic. But for your Core Business Loops—the agents that touch your customers and drive your revenue—generalists are a competitive disadvantage. They are too expensive to scale and too average to stand out. Our work with this Marketing Automation platform proves that Specialization is the new Frontier. By combining Distributional RL (to find the outliers) with Agentic Reranking (to ensure safety), you can build agents that swing for the fences without striking out on your budget. You don't need a bigger model to win. You need a smarter one.Want to see the difference? Try our Distributional RL model and Standard RL baseline on Hugging Face. Ready to build specialized AI agents for your business? Request Early Access or reach out at contact@vizops.ai