The Prompt Optimization Playbook: Which Method Wins Where
By Rishav ·
March 8, 2026 ·
14 min read
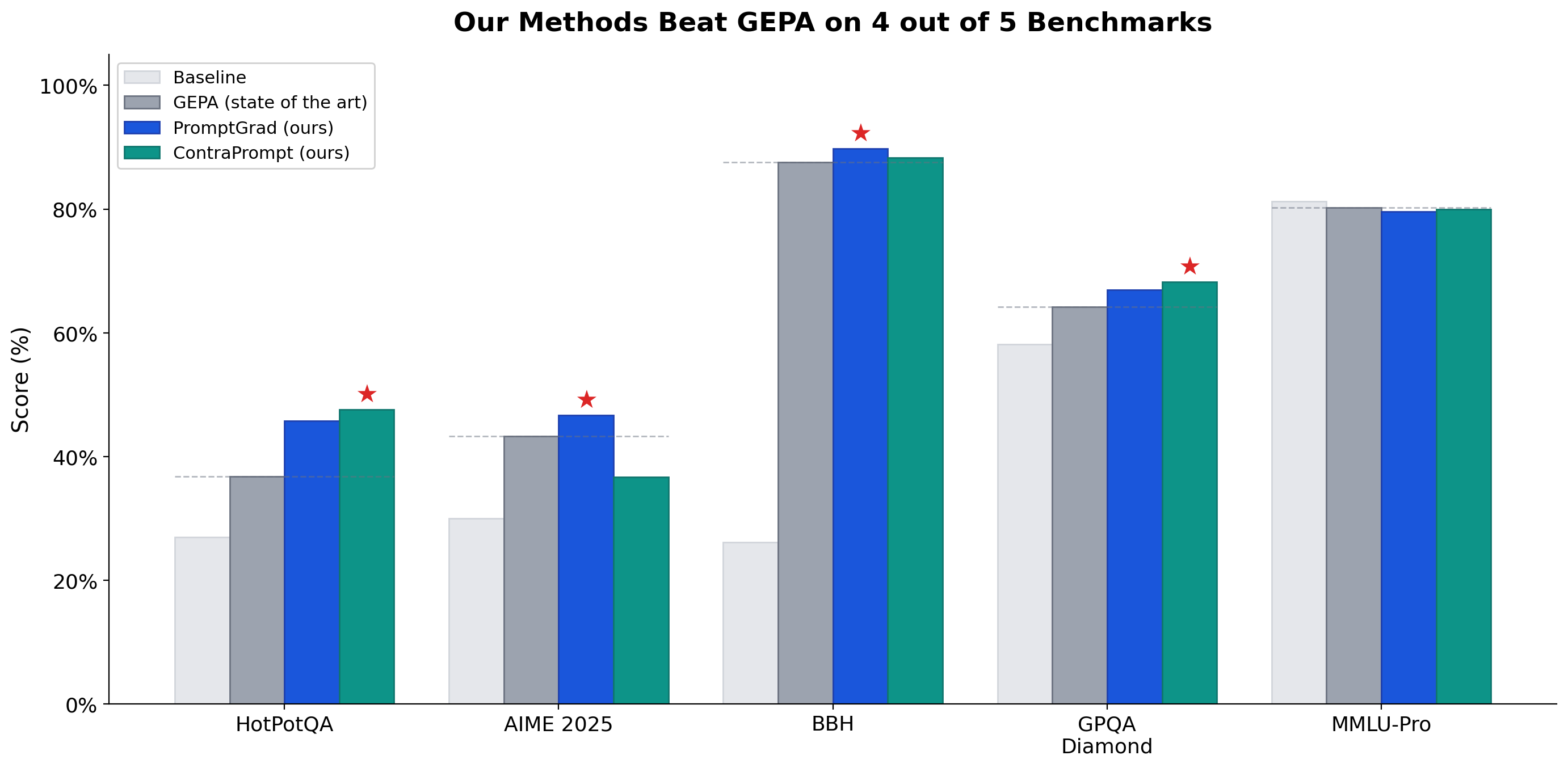
We win 4 out of 5 benchmarks. The previous state of the art isn't close.
We built two prompt optimization methods — PromptGrad (gradient-based) and ContraPrompt (contrastive learning) — and tested them head-to-head against GEPA, the previous state of the art, across five benchmarks. On every reasoning benchmark in the study, our methods beat GEPA. The only task where GEPA holds a marginal lead is MMLU-Pro — a knowledge-recall benchmark where no optimizer can help because you can't teach a model facts through prompting.
The interesting part: PromptGrad and ContraPrompt win on completely different tasks with zero overlap. PromptGrad dominates competition math and diverse reasoning. ContraPrompt dominates multi-hop QA and graduate science. Neither touches the other's territory.
There is no universal best prompt optimizer. The right choice depends on your task. Getting this decision right matters more than any single technique — because the wrong optimizer can actively hurt performance (ContraPrompt on AIME: -15%). This post gives you the framework to make that call.
Executive Summary
- We win 4 out of 5 benchmarks against GEPA, the previous state of the art. PromptGrad at +18%, ContraPrompt at +14% — on every reasoning task in the study, our methods come out ahead
- GEPA's only win is MMLU-Pro, a knowledge-recall task where no optimizer can help — you can't teach a model facts through prompting
- PromptGrad and ContraPrompt dominate different tasks — PromptGrad where failures are systematic and low-variance, ContraPrompt where failures are high-variance with self-correction potential
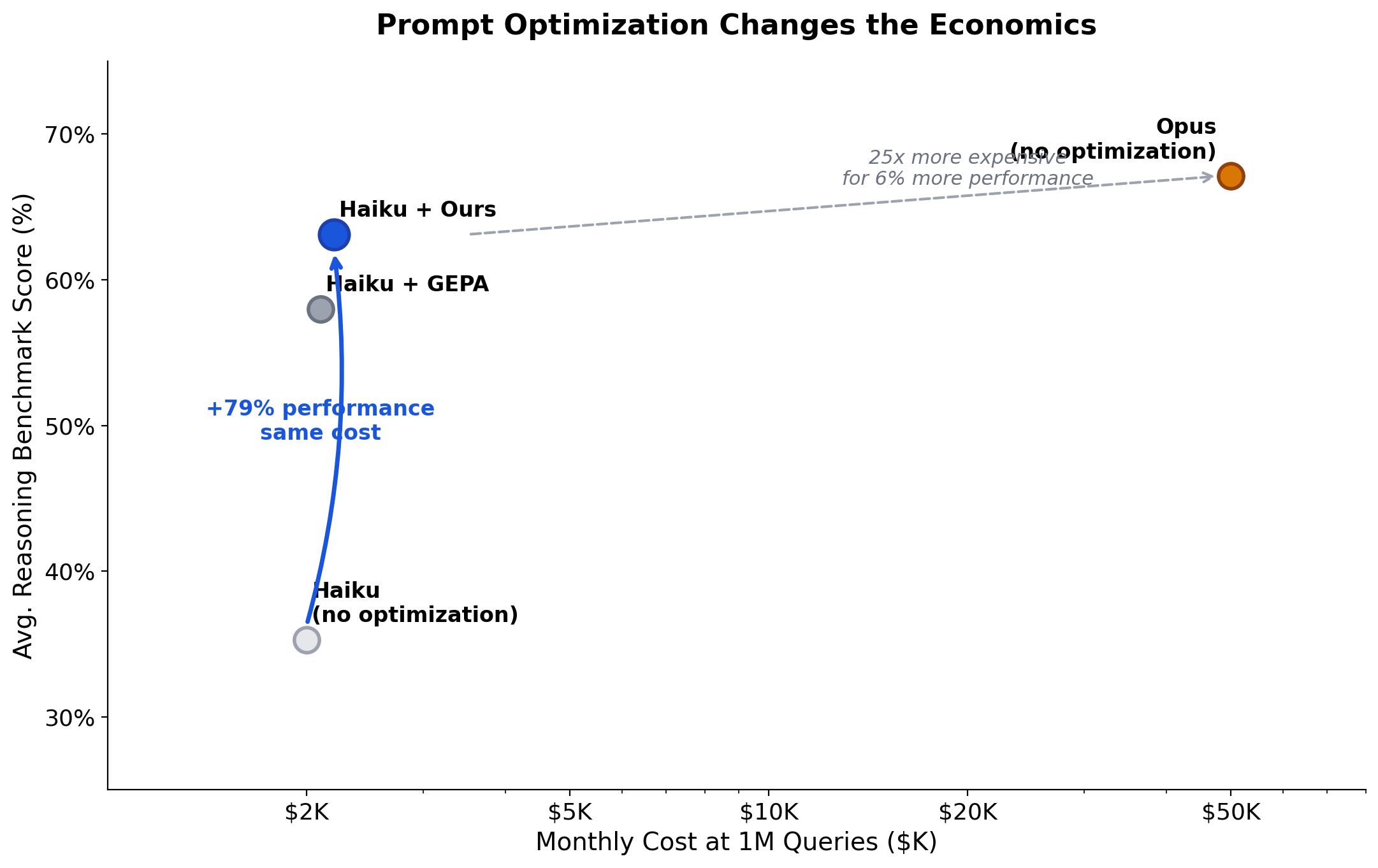
- Prompt optimization can't fix knowledge gaps, but it delivers 3–29% gains on reasoning tasks
- The practical impact: optimized small models close 50–70% of the performance gap with models costing 30–60× more
The Full Results
Five benchmarks. Three optimizers. We win four.
| Benchmark | Task Type | Baseline | GEPA | PromptGrad | ContraPrompt | Winner | Delta vs GEPA |
|---|
| HotPotQA | Multi-hop reasoning | 27.0% | 36.8% | 45.8% | 47.6% | ContraPrompt | +10.8 pts |
|---|
| AIME 2025 | Competition math | 30.0% | 43.3% | 46.7% | 36.7% | PromptGrad | +3.4 pts |
| BBH | 27 diverse tasks | 26.1% | 87.6% | 89.8% | 88.3% | PromptGrad | +2.2 pts |
|---|
| GPQA Diamond | Graduate science | 58.1% | 64.2% | 66.9% | 68.2% | ContraPrompt | +4.0 pts |
| MMLU-Pro | Professional knowledge | 81.2% | 80.2% | 79.6% | 80.0% | GEPA | -0.2 pts |
|---|
Reading the deltas: HotPotQA's +10.8 points is a 29% relative improvement over what was previously the best method available. AIME's +3.4 points is on competition math where every point represents problems that stumped most human contestants. BBH's gap looks small until you realize GEPA already pushed this from a 26.1% baseline — we squeezed more out of an already-optimized benchmark. GPQA Diamond's +4 points is on PhD-qualifying science questions.
Normalized Performance
Raw scores are misleading — a 3% gain where baseline is 87% means something very different from a 3% gain where baseline is 27%. Normalizing to a 0–1 scale per benchmark gives the fair comparison:
| Method | Normalized Score | vs. GEPA |
|---|
| Baseline | 0.200 | — |
|---|
| GEPA (state of the art) | 0.641 | — |
| ContraPrompt | 0.730 | +14% |
|---|
| PromptGrad | 0.755 | +18% |
Both methods significantly outperform the current state of the art. Together, they cover more ground than either alone.
Three Philosophies of Optimization
Each method embodies a fundamentally different theory of how to improve prompts. Understanding the philosophy tells you when to deploy it.
GEPA: The Explorer
"Generate many variants. Test them all. Keep the best."
GEPA treats prompt optimization as evolution. It creates a population of prompt variants, evaluates them on training data, and selects survivors through Pareto optimization — balancing performance against prompt simplicity. A strong reflection model guides mutations.
It's like A/B testing at massive scale. You try hundreds of options and pick the winner. You don't know why it won, but you know it did.
Strength: Reliable, hard to catastrophically break. Good default when you don't understand your failure modes.
Limitation: Black box. Can't discover targeted reasoning fixes. Hits a ceiling on tasks requiring deep, systematic reasoning improvements.
PromptGrad: The Diagnostician
"Analyze specific failures. Extract targeted fixes. Validate each one independently."
PromptGrad treats optimization like evidence-based medicine. It examines symptoms (failures), proposes treatments (rules), runs a controlled trial on each treatment (per-rule validation on 15 held-out examples), and only prescribes what's statistically proven to work.
It's like a doctor who tests every intervention before adding it to your treatment plan. Slower and more expensive, but you trust the results — and when something goes wrong, you know exactly which rule to adjust.
Strength: Explainable results, statistical guarantees against overfitting, comprehensive coverage through stratified sampling. The most reliable choice when you need auditability.
Limitation: Higher compute cost. May miss non-obvious improvements that broader evolutionary search would find. Requires diverse failures to extract good rules.
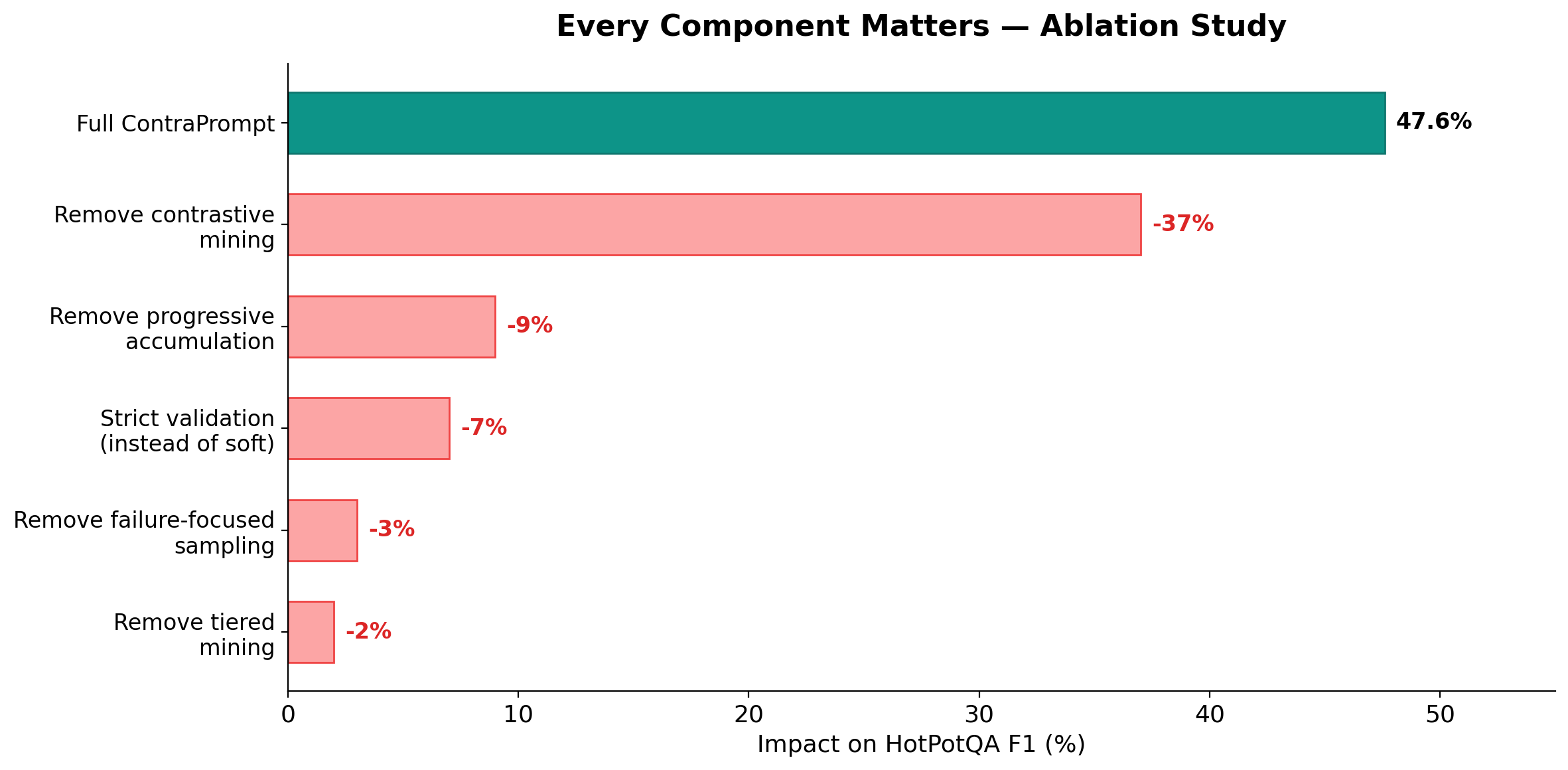
The evidence: Disabling rule validation alone drops performance by 14%. This single mechanism — testing every proposed rule on 15 held-out examples at p<0.05 significance before accepting it — is what separates evidence-based optimization from evolutionary guesswork. On MATH-500 where the baseline was already 82%, the validation gate rejected 27 out of 29 proposed rules in the first epoch because none measurably helped. That's the system refusing to add noise to an already-good prompt.
ContraPrompt: The Learning Coach
"Watch the model fail, then succeed. Extract what changed."
ContraPrompt is like a coach studying game film — not just the losses, but the specific moments where the team fell behind and came back. By comparing failure and success on the same problem, it isolates the exact reasoning strategies that were missing.
It's like studying comeback wins. The patterns that turn losses into victories are the most valuable plays in the book.
Strength: Discovers self-correction strategies no other method can find. Naturally focuses on the highest-leverage improvements. Soft validation captures compound effects.
Limitation: Entirely dependent on retry success rate. If the model can't self-correct with a nudge, there's nothing to mine. Underperforms on tasks where failures are fundamental capability limits.
The evidence: Removing contrastive mining entirely drops HotPotQA performance by 37%. No other component comes close. Progressive rule accumulation — letting rules build on each other instead of resetting — accounts for 9%. Soft validation (keeping rules unless they actively hurt, rather than demanding each independently prove itself) is worth 6 to 8 points. At our default threshold we keep 28 rules and score 47.6%. Strict validation keeps only 14 rules and scores 41.3%. Individually neutral rules help in combination, and soft validation captures that.
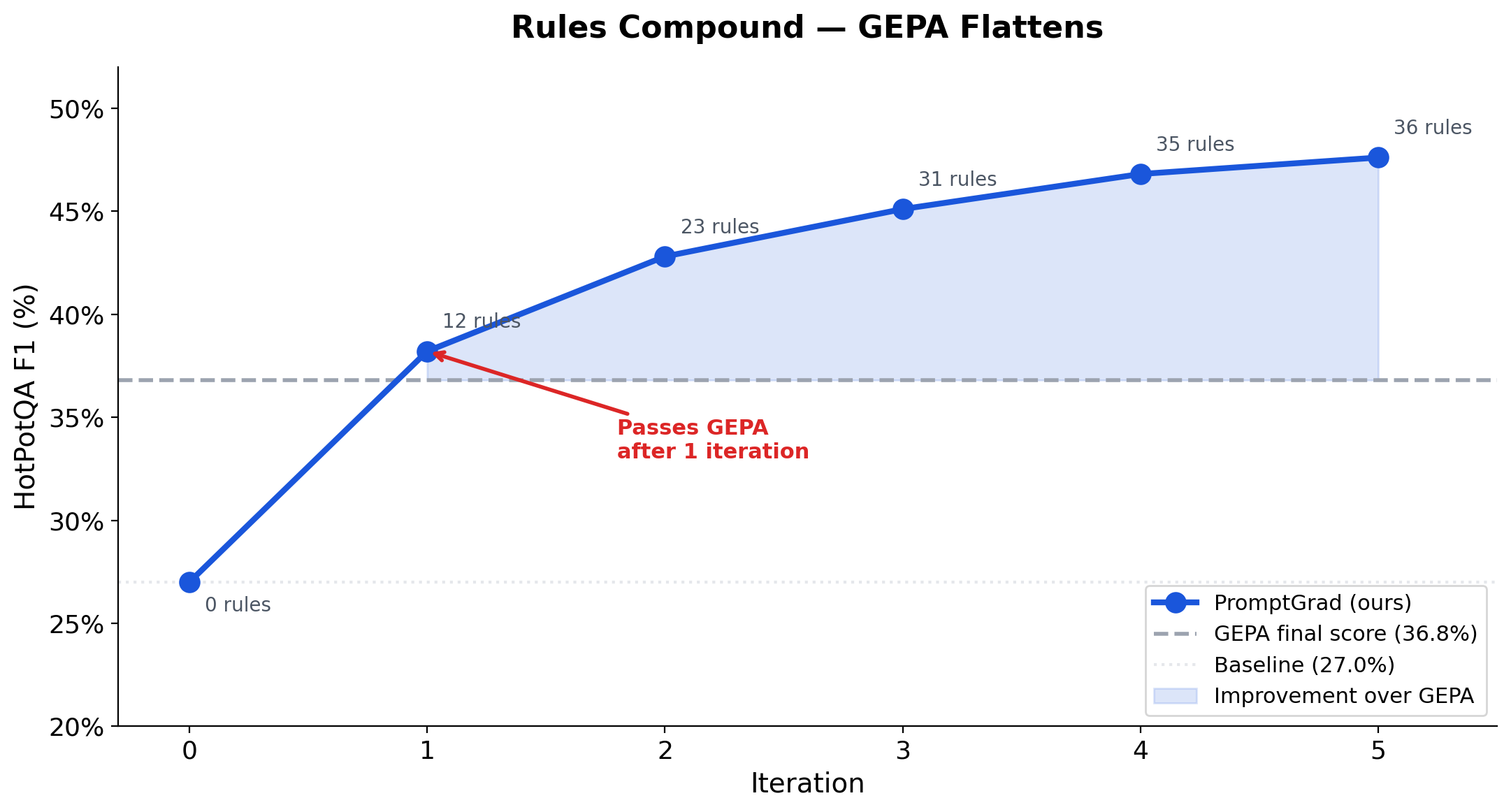
Rules Compound — GEPA Flattens
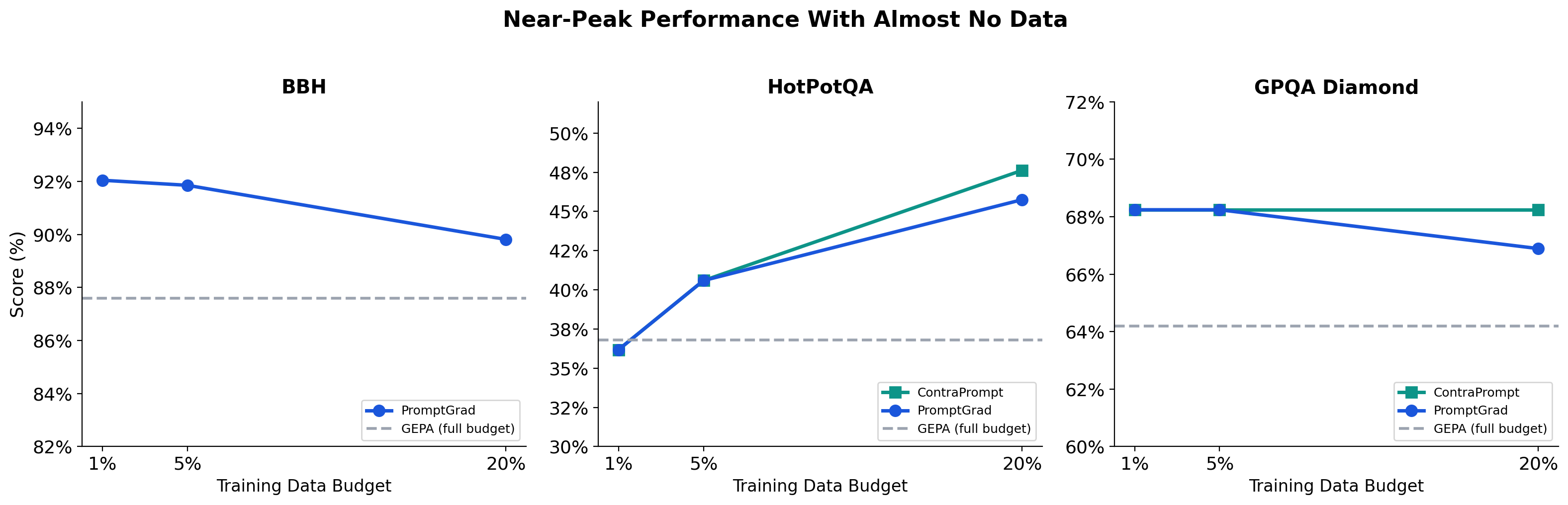
The ablation data shows which components matter. The iteration data shows how they compound.
PromptGrad on HotPotQA, iteration by iteration:
| 0 (start) | 27.0% | 0 | Baseline — no optimization |
|---|
| 1 | 38.2% | 12 | Already passes GEPA (36.8%) |
| 2 | 42.8% | 23 | +4.6 pts from 11 new rules |
|---|
| 3 | 45.1% | 31 | Gains tapering but still climbing |
| 4 | 46.8% | 35 | |
|---|
| 5 | 47.6% | 36 | Final — 10.8 pts above GEPA |
GEPA's final score on the same benchmark: 36.8%. We pass GEPA after a single iteration and keep climbing. By iteration 5, we've accumulated 10.8 points of advantage.
ContraPrompt tells the same story from the mining side: 46% of examples yield contrastive pairs in iteration 1, dropping to 36%, 28%, 18%, 10% by iteration 5. The optimizer exhausts its own signal because the model keeps getting better — there are fewer failures left to mine.
The Decision Framework
Question 1: Is your task reasoning-bound or knowledge-bound?
This is the first and most important filter.
Knowledge-bound tasks (factual QA, trivia, domain knowledge recall): Prompt optimization delivers minimal gains. Across all three methods, MMLU-Pro showed less than 1% movement. You can't teach a model facts through prompting. Invest in retrieval (RAG) instead.
Reasoning-bound tasks (multi-step analysis, evidence synthesis, mathematical reasoning, complex Q&A): Prompt optimization delivers dramatic gains — 3% to 29% depending on method and task. Continue to Question 2.
Question 2: How variable are your model's failures?
This is the core diagnostic. The key insight: failure variance determines which optimizer can extract a useful learning signal.
Across all five benchmarks, the correlation between retry success rate and ContraPrompt's improvement over GEPA is r=0.90, p<0.05. It's the single strongest predictor of which optimizer wins — turning this qualitative recommendation into a quantitative one.
Run a quick retry probe — take 20 failed examples, re-run them with a nudge like "Think more carefully," and count successes.
- Meaningful retry success (high-variance failures) → ContraPrompt. The model sometimes succeeds and sometimes fails on similar inputs. ContraPrompt leverages exactly this contrast — comparing failures and successes on the same problem to isolate the missing reasoning strategies. This is why it dominates on retrieval-augmented QA (HotPotQA), multi-label domain classification (GDPR-Bench), and expert-level reasoning (GPQA). Its grouped synthesis writes a targeted rule for each failure category.
- Retry success near zero (low-variance, systematic failures) → PromptGrad. The model fails consistently and predictably regardless of retry. PromptGrad doesn't need successful retries — consistent failure patterns are sufficient for its gradient computation. Its strict per-rule validation acts as a strong regularizer, which is why it accepted only 2 of 54 candidate rules on MATH-500 while still improving performance.
- Borderline → Test both. The cost of running both (~$1 total) is negligible compared to the deployment value.
Question 3: What does your baseline look like?
- High baseline already (>75%) → PromptGrad. When the model is near its capability ceiling, systematic failures dominate and PromptGrad's strict validation prevents overfitting to noise.